mysql隔离级别
ACID是一组数据库事务属性,用来保证即使在有错误,或断电等情况下数据库数据的正确性。
具体来说,隔离的定义是: 并发访问数据库时,一个用户的事务不被其他事务所干扰,各并发事务之间数据库是独立的。
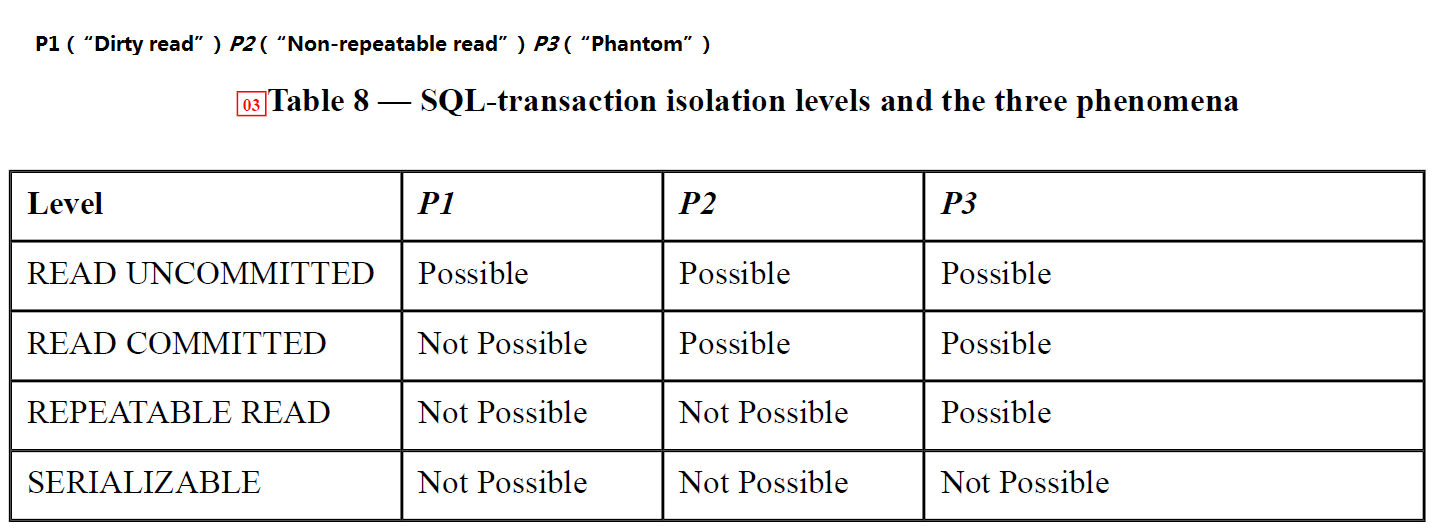
在数据库系统中,人们定义了4个隔离级别:读未提交,读已提交,可重复读和可串行化。有一些读取现象,例如脏读取,不可重复读取,幻像读取和写倾斜。
- Read Uncommitted(读未提交) 在该隔离级别,所有事务都可以看到其他未提交事务的执行结果。本隔离级别很少用于实际应用,因为它的性能也不比其他级别好多少。读取未提交的数据,也被称之为脏读(Dirty Read)。
- Read Committed(读已提交) 一个事务只能看见已经提交事务所做的改变。这种隔离级别也支持所谓的不可重复读(Nonrepeatable Read),因为同一事务的其他实例在该实例处理其间可能会有新的commit,所以同一select可能返回不同结果。
- Repeatable Read(可重读) 这是MySQL的默认事务隔离级别,它确保同一事务的多个实例在并发读取数据时,会看到同样的数据行。不过理论上,这会导致另一个棘手的问题:幻读 (Phantom Read)。简单的说,幻读指当用户读取某一范围的数据行时,另一个事务又在该范围内插入了新行,当用户再读取该范围的数据行时,会发现有新的“幻影” 行。InnoDB存储引擎通过多版本并发控制(MVCC,Multiversion Concurrency Control)机制解决了该问题。
- Serializable(可串行化) 这是最高的隔离级别,它通过强制事务排序,使之不可能相互冲突,从而解决幻读问题。简言之,它是在每个读的数据行上加上共享锁。在这个级别,可能导致大量的超时现象和锁竞争。 这四种隔离级别采取不同的锁类型来实现。并发控制中读取同一个表的数据,可能出现如下问题:
脏读(Drity Read):事务T1修改了一行数据,事务T2在事务T1提交之前读到了该行数据。
不可重复读(Non-repeatable read): 事务T1读取了一行数据。 事务T2接着修改或者删除了改行数据,当T1再次读取同一行数据的时候,读到的数据时修改之后的或者发现已经被删除。
幻读(Phantom Read): 事务T1读取了满足某条件的一个数据集,事务T2插入了一行或者多行数据满足了T1的选择条件,导致事务T1再次使用同样的选择条件读取的时候,得到了比第一次读取更多的数据集。
这是隔离级别和读现象之间的矩阵:
我将运行一些测试来验证这些结论,方法是:我尝试起动2个并发事务。具体来说,我打开了2个终端选项卡,每个选项卡都作为一个数据库连接打开。在第一个连接上,我将首先用begin关键字开启一个事务,暂时不调用rollback或commit,这样就可以支持长时间的查询了。同时,在第2个终端,我将运行一些查询以进行测试。
此测试在mysql5.7上运行。
- 测试未提交隔离级别
该测试将显示,尽管第个事务尚未完成,但它可以在第二个事务中看到一些“脏数据”。
第一个终端:在开启事务之前,我们将隔离级别临时设置为READ UNCOMMITTED。然后我们查询以获得样本数据。
SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
BEGIN;
SELECT year FROM foo WHERE id = 1; -- return 1993
第二个终端:我们创建一个新事务,然后更新同一记录不提交事务。
BEGIN;
UPDATE foo SET year = 2019 WHERE id = 1;
第一个终端:在同一个事务中,我们尝试再次获得相同的记录。但是此时,我们从获得了第二个事务更新的新数据。
SELECT year FROM foo WHERE id = 1; -- return 2019
COMMIT;
在现实中,这种行为很危险,因为第二个事务可能失败并回滚,或者我们只能看到一个事务的中间状态。此行为很容易导致数据不一致。
如果我们再次尝试上述所有步骤,但将隔离级别从未提交更改为读已提交,则在最后一个查询中返回的数据仍为1993。
SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED;
2.测试READ COMMITTED隔离级别
该测试将表明,在读已提交隔离级别中,我们有一个问题:在同一事务中,一行被检索两次,并且两次读取之间的值不同。
在第一个终端上:作为测试1,我们设置隔离级别并查询一些数据。
SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED;
BEGIN;
SELECT COUNT(*) FROM foo WHERE year <= 1995; -- total 3 rows
*************************** 1. row ***************************
count(*): 3
1 row in set (0.000 sec)
在第二个终端上:我们尝试将一条记录更新为新值。此更新将影响上一个事务的查询结果。
BEGIN;
UPDATE foo SET year = 2019 WHERE id = 1;
COMMIT;
同样,在第一个终端上,在没有关闭事务的情况下,我们再次运行相同的查询,并发现在同一事务中,相同的查询数据可能会有所不同。
SELECT COUNT(*) FROM foo WHERE year <= 1995; -- return 2
COMMIT;
*************************** 1. row ***************************
count(*): 3
1 row in set (0.000 sec)
如果我们将隔离性从读已提交提高到可重复读,则将解决此问题。
3.测试REPEATABLE READ隔离级别
在此测试中,我想证明,如果我们使用REPEATABLE READ隔离级别,我们将遇到“幻读”问题:在同一事务上,当我们在其他事务上插入新记录时,同一查询有2个不同的结果。
在第一个终端上:
SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ;
BEGIN;
SELECT COUNT(*) FROM foo WHERE year <= 1995; -- return 3
在第二个终端上,我尝试插入一条记录:
BEGIN;
INSERT INTO `foo` (name, year) VALUES (“foo_foo”, 1995);
COMMIT;
在第一个终端上,我尝试再次运行相同的查询,并期望结果将从3变为4,因为可重复读无法检测到幻读:
SELECT COUNT(*) FROM foo WHERE year <= 1995; -- return 3
*************************** 1. row ***************************
count(*): 3
1 row in set (0.000 sec)
这不是我们所期望的。因此,我又尝试了一步,尝试更新插入的记录,希望它会失败:
UPDATE foo SET year = 2019 WHERE name = ‘foo_foo’;
COMMIT;
Query OK, 1 row affected (0.000 sec)
Rows matched: 1 Changed: 1 Warnings: 0
看起来执行成功了,我再次通过查询进行测试以进行确认:
SELECT * FROM foo WHERE name = ‘foo_foo’;
*************************** 1. row ***************************
id: 7
name: foo_foo
year: 2019
1 row in set (0.000 sec)
因此,基于这2个测试,我对MySQL的REPEATABLE READ隔离级别有一些总结:
- 当使用select语句时,不会像SQL标准提到的那样幻读。
- 当事务修改数据(写入/删除/更新)时,我们可以成功地写入“看不见的数据”。该行为是可重复读(未修改的行不可见)和已提交读(已修改的行可见)的混合行为。
4.测试SERIALIZABLE隔离级别
最后,我尝试检查最后的隔离级别:Serializable隔离级别。
第一个终端:
SET SESSION TRANSACTION ISOLATION LEVEL SERIALIZABLE;
BEGIN;
SELECT COUNT(*) FROM foo WHERE year <= 1995; -- return 3 as usual
在第二个终端上:我尝试插入新记录。
BEGIN;
INSERT INTO `foo` (name, year) VALUES (“foo_foo”, 1996); — waiting
COMMIT;
我们看到第二个事务被阻塞了。或者,换句话说,第个事务被锁定并等待第一个事务完成。
因此,在第一个终端上,我们COMMIT;之后,第二个终端上的事务将自动完成。
参考:
http://mysql.taobao.org/monthly/2017/06/07/
https://medium.com/@huynhquangthao/mysql-testing-isolation-levels-650a0d0fae75